
智驾新突破!
作者/ IT时报记者 毛宇
编辑/ 郝俊慧 孙妍
7月26日,2025世界人工智能大会(以下称WAIC 2025)“模数引领 智行未来—AI赋能自动驾驶创新发展论坛”上,新一批智能网联汽车示范运营证正式发放,小马易行科技(上海)有限公司、百度智行科技(上海)有限公司、赛可智能科技(上海)有限公司、上海强生出租汽车有限公司、上海友道智途科技有限公司等8家企业成为首批获准企业。

该运营证覆盖智能出租与智能货运两大业态,是在《浦东新区促进无驾驶人智能网联汽车创新应用规定》立法支持下,多部门联合组织下发放的,标志着上海智能网联汽车示范运营迈入常态化、规模化的新阶段,是智能驾驶领域的一次重大突破。
也就是说,此次获得牌照的企业,可以在试点区域运营“主驾无人”汽车,此前上海已有的试点区域和车辆均为“主驾有人”。据了解,随着浦东新区第三批自动驾驶测试道路的开放,上海市累计开放测试道路里程已突破2700公里,覆盖部分内环范围的中心城区。
上海市经济和信息化委员会二级巡视员、汽车产业处处长韩大东在大会上透露,上海将有序扩大自动驾驶的开放区域,“实现浦东新区全域开放,同步推动奉贤、闵行等区域开放,并联通本市四大测试区域的开放道路”。
作为首批获准企业,小马智行将联合上海锦江集团旗下锦江出租,以浦东金桥和花木核心区域为起点,逐步向公众开放自动驾驶出行服务。乘客在金桥地区的运营范围内,只需通过“小马智行”App或同名微信、支付宝小程序,即可一键呼叫Robotaxi。
当天发布的上海《模速智行行动计划》提出,到2027年,实现L4级自动驾驶载客突破600万人次,开放道路超5000公里,具备L2和L3功能的新车占比超90%。
世界模型
以虚拟仿真突破数据瓶颈
智能驾驶的技术演进正经历着从“模仿人类”到“理解世界”的深刻变革。
在论坛上演示的上海高级别自动驾驶实训场仿真实验室里,一组组复杂的交通场景数据正通过“采、洗、标、测、用”这“五位一体”的工具链完成转化,支撑算法模型系统化训练。
商汤科技联合创始人王晓刚展示的世界模型,为行业提供了突破数据瓶颈的新思路:通过3D高斯重建技术对施工占道场景进行数字孪生,该模型能模拟车辆在不同光照、天气条件下的各类应对方案,通过强化学习自主优化驾驶策略。
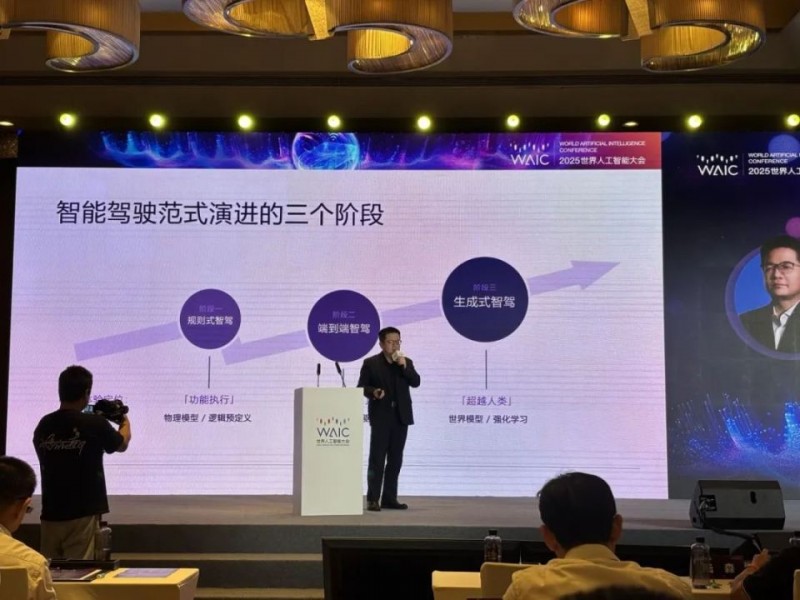
这种“虚拟训练-现实验证”的闭环,使原本需要百万公里实车采集的场景数据,通过算法生成实现高效覆盖。王晓刚表示:“世界模型不限于自动驾驶,也正向具身智能领域演进。”
上汽智己作为此次同时支持两家运营公司申请牌照的车企,与吉利极氪的实践则呈现了量产进程中的技术融合。上汽智己副首席技术官、智能驾驶首席科学家郭辉提出的L2/L3/L4一体化架构,通过多模态大模型嵌入常识性知识,解决了端到端算法中的因果混淆问题。
在极氪9X车型上,双Thor芯片构建的1400TOPS算力平台,支撑着互为冗余的双端到端模型,使L3级自动驾驶在复杂路口的决策响应速度大幅提升。这种“硬件冗余+算法协同”的方案,印证了技术创新必须与工程化落地紧密结合。

然而,技术跃进仍面临现实制约。博世智能驾控中国区总裁吴永桥直指行业痛点,“当前多模态特征对齐难度大、数据获取与训练不易,最难的是智驾芯片的存储带宽限制,使VLA(Vision Language Action 视觉—语言—动作)大模型难以实现实时控车,因此一段式端到端短期落地困难。”吴永桥认为,一段式端到端仍是智驾量产核心,眼下“渐进式突破”的路径,正逐步实现技术理想与产业现实的动态平衡。
安全体系
智能驾驶的“生命线工程”
安全不是技术指标的堆砌,而是要让用户敢于把生命托付给系统,这需要技术与制度双轮驱动。
交通语料正是连接技术创新与安全落地的重要纽带。 在同济大学交通学院的实验室里,涂辉招教授团队与库帕思合作构建的“数据来源—行业应用—知识体系”三维魔方体系,正为安全决策提供底层支撑。
该体系覆盖14类数据源、8大交通行业,通过解析会议论文、专业知识库、政策文件等构建知识图谱,将原始交通数据转化为“可理解、可推理”的智能决策依据。其与上海市交通委“数治通”“数享通”“数业通”场景结合后,能在具体场景中发挥显著作用——以高速合流区为例,融入“能见度低于200米时车速不超60公里、车距保持100米以上”等法规语料的强化学习模型,可让智能车快速适应复杂规则,显著提升稳定性。涂辉招强调,在人机混驾时代,交通语料对智能车遵循规则、提升决策合理性至关重要。

法规适配则为安全落地划定清晰边界。上海新发放的示范运营证中,申请企业须配备经过培训考核合格的安全员,保障“主驾无人”试点有序推进;此外,申报流程通过“一网通办”平台进一步优化,实现“只跑一次、一次办成”,营造更优营商环境。这不仅是技术与政策协同落地的重要体现,也为上海高阶自动驾驶示范推广提供了坚实支撑。
但是,潜在风险仍需警惕。百度自动驾驶安全与政策首席专家吴琼指出,当前产业已从技术可行性验证转向产业化,制度匹配性、法规适配性成为关键,驾驶义务转移是核心矛盾——传统驾驶中发生事故的责任人主要是驾驶人,自动驾驶阶段还需法律明确系统责任。
不过安全性已获初步验证,百度萝卜快跑1.7亿公里测试里程的出险率仅为人类的1/14,Waymo数据也显示自动驾驶风险大幅低于人类驾驶。吴琼呼吁加快道路交通法规修订、明确责任划分,以制度创新破解产业化瓶颈。
上海
2027年九成新车为L2级以上
“过去,中国需要博世;现在,博世需要中国。”吴永桥在论坛上的论断,道出中国智能驾驶领域在全球格局中的崛起态势。
过去一年,仅上海市新能源汽车累计推广量就达164.5万辆,稳居全球城市首位;其汽车产业规模以上产值突破7035亿元,集聚9家整车企业、600余家零部件企业及15万名高端人才,构建起全球最完整的产业链生态。
更具突破性的是数据治理模式。论坛上,上海临港新片区正式发布《智能网联汽车出海行动方案》,围绕数据跨境合规、数据加工、传输通道、算力统筹与集聚载体五大核心环节,构建“全链条贯通、全要素融通、全球化联通”的出海服务体系。
方案明确建立数据出境“绿色通道”,发布“负面清单+操作指引”双机制,为企业数据出海保驾护航。比如,通过“负面清单”清晰界定哪些数据严禁出境,让企业明确红线所在;“操作指引”则详细指导企业如何合规地进行数据出境操作,从申请流程到技术规范,一一给予说明,极大提升了企业数据跨境的可操作性与安全性。
与此同时,中国智驾企业在海外市场动作频频。

7月16日,百度萝卜快跑与全球最大的移动出行服务平台Uber达成战略合作,数千辆萝卜快跑自动驾驶汽车将接入Uber全球出行网络。文远知行的自动驾驶小巴Robobus与新加坡RWS圣淘沙名胜世界达成合作,2024年6月至今,文远小巴已为该地累计安全运送数万名乘客,完成数千次自动驾驶接驳服务。小马智行则与新加坡出租车运营商康福德高集团签署合作备忘录,共同推动自动驾驶出租车的大规模商业运营。
标准话语权的提升成为关键突破口。
近日,由我国牵头制定的国际标准ISO 34505:2025《道路车辆自动驾驶系统测试场景 场景评价与测试用例生成》正式发布。新的国际标准主要规定了自动驾驶系统测试场景的评价流程与试验方法,明确测试场景暴露率、复杂度、危险度等评价指标的判定要求,并定义了测试用例生成的一般性方法及其必要特征。该标准也为全球智能驾驶提供了“安全可控、可持续发展”的实践样本。
排版/ 季嘉颖
图片/ IT时报 WAIC 东方IC
来源/《IT时报》公众号vittimes
E N D